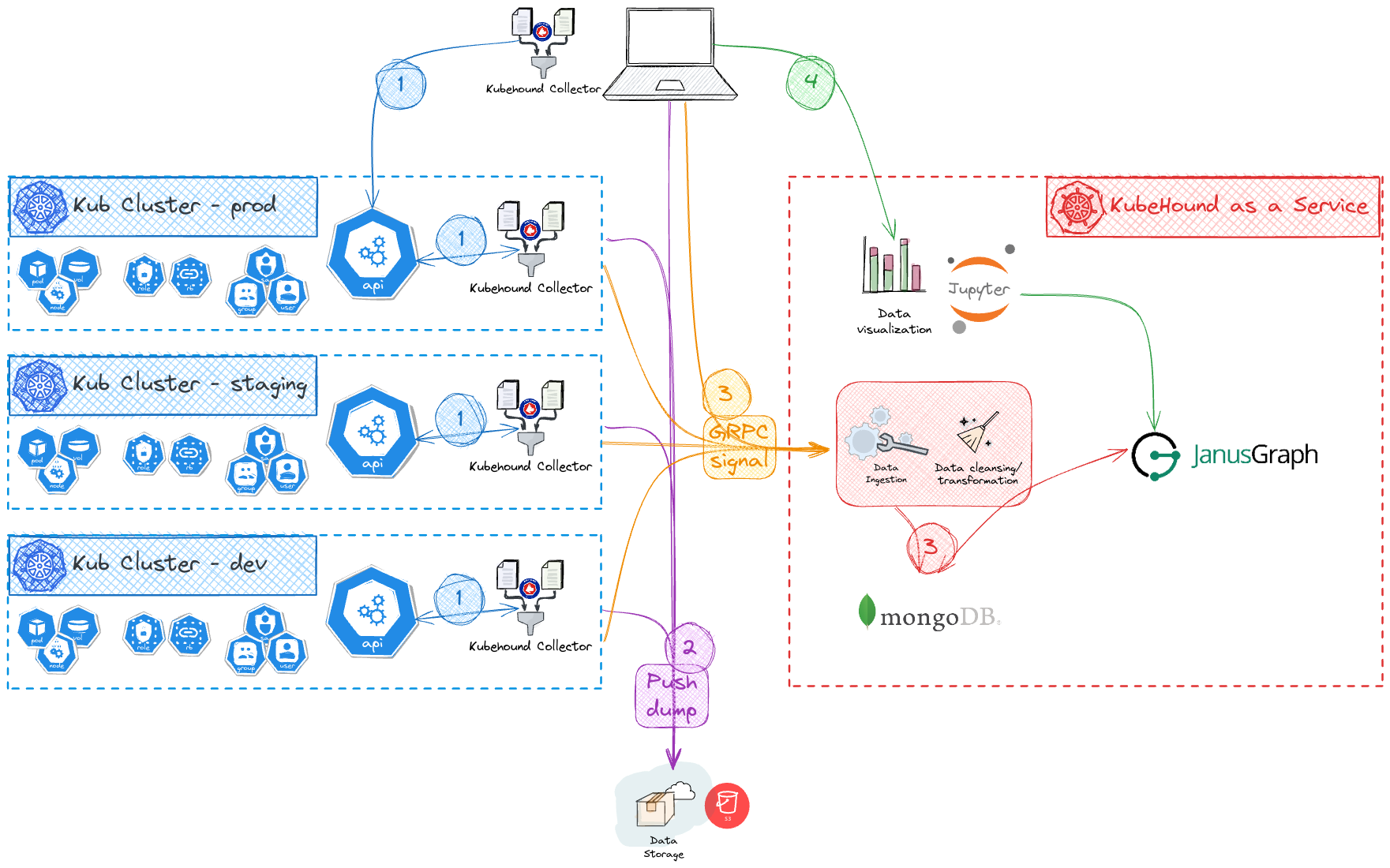
KubeHound as a Service (KHaaS)
KHaaS enables you to use KubeHound in a distributive way. It is split in 2 main categories:
- The ingestor stack which includes the
graphdb,storedb,UIandgrpc endpoint. - The collector (the kubehound binary) which will dump and send the k8s resources to the KHaaS
grpc endpoint.
Note
You need to deploy the data storage you want to use (AWS s3 in our example).
Automatic collection
KHaaS has been created to be deployed inside a kubernetes cluster. This eases scaling and allows you to set Kubernetes CronJob daily dumps of your infrastucture for instance. To configure and deploy it, please refer to the deployment section.
Manual collection
In order to use kubehound with KHaaS, you need to specify the api endpoint you want to use. Since this is not likely to change in your environment, we recommend using the local config file. By default KubeHound will look for ./kubehound.yaml or $HOME/.config/kubehound.yaml. For instance if the default configuration we set the endpoint with disabled SSL:
ingestor:
blob:
bucket_url: "" # (i.e.: s3://your-bucket)
region: "us-east-1" # (i.e.: us-east-1)
api:
endpoint: "127.0.0.1:9000"
insecure: true
Note
You can use kubehound-reference.yaml as an example which list every options.
Once everything is configured you just run the following, it will:
- dump the k8s resources and push it compressed to the cloud storage provider.
- send a grpc call to run the ingestion on the KHaaS grpc endpoint.
Manual ingestion
If you want to rehydrate (reingesting all the latest clusters dumps), you can use the ingest command to run it.
You can also specify a specific dump by using the --cluster and run_id flags.